
裁剪:裁剪部亚洲色图 中文字幕
【新智元导读】谷歌DeepMind的小模子核弹来了,Gemma 2 2B成功打败了参数大几个数目级的GPT-3.5和Mixtral 8x7B!而同期发布的Gemma Scope,如显微镜一般突破LLM黑箱,让咱们看清Gemma 2是若何有盘算的。
谷歌DeepMind的小模子,又上新了!
就在刚刚,谷歌DeepMind发布Gemma 2 2B。


它是从Gemma 2 27B中蒸馏而来。
固然它的参数只消2.6B,但在LMSYS竞技场上的得分,一经超过了GPT-3.5和Mixtral 8x7B!

在MMLU和MBPP基准测试中,它分离取得了56.1和36.6的优异收获;比起前代模子Gemma 1 2B,它的性能起始了10%。
小模子打败了大几个数目级的大模子,再一次印证了最近业界相配看好的小模子标的。

谷歌在今天,一共公布了Gemma 2家眷的三个新成员:
Gemma 2 2B:轻量级2B模子,在性能和效果之间好意思满了最大的均衡ShieldGemma:基于Gemma 2构建的安全内容分类器模子,用于过滤AI模子的输入和输出,确保用户安全Gemma Scope:一种可施展性器具,提供对模子里面运改变制的无与伦比的洞悉
6月,27B和9B Gemma 2模子降生。
自愿布以来,27B模子赶紧成为大模子名次榜上,排名前哨的开源模子之一,以致在实质对话中发扬起始了参数数目大两倍的流行模子。

Gemma 2 2B:即刻在设备上使用
轻量级小模子Gemma 2 2B,是从大模子中蒸馏而来,性能绝不忘形。
在大模子竞技场LMSYS上,新模子取得令东谈主印象深化的1130分,与10倍参数的模子不相高下。
GPT-3.5-Turbo-0613得分为1117,Mixtral-8x7b得分为1114。

足见,Gemma 2 2B是最好的端侧模子。

有网友在iPhone 15 Pro上,让量化后的Gemma 2 2B在MLX Swift上运转,速率快到惊东谈主。

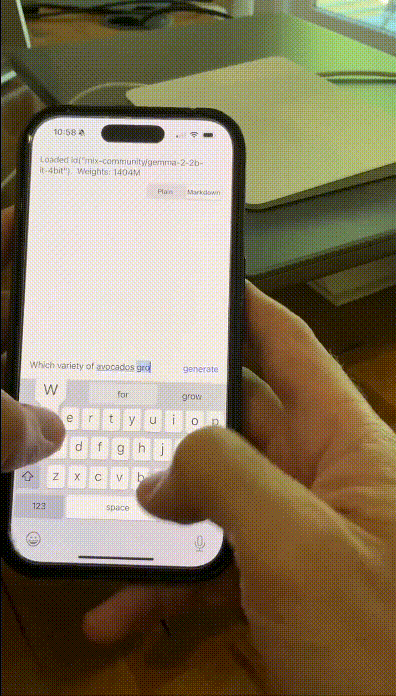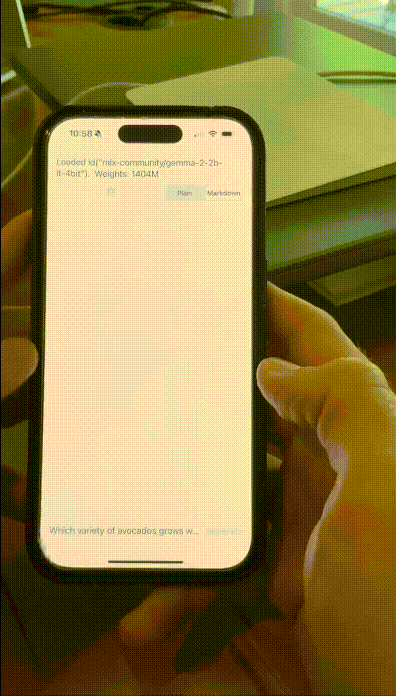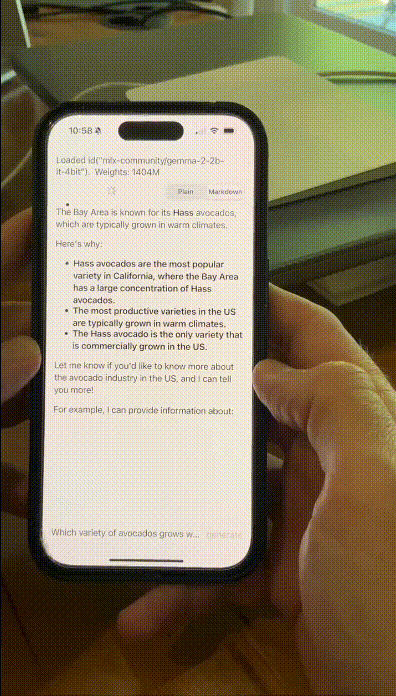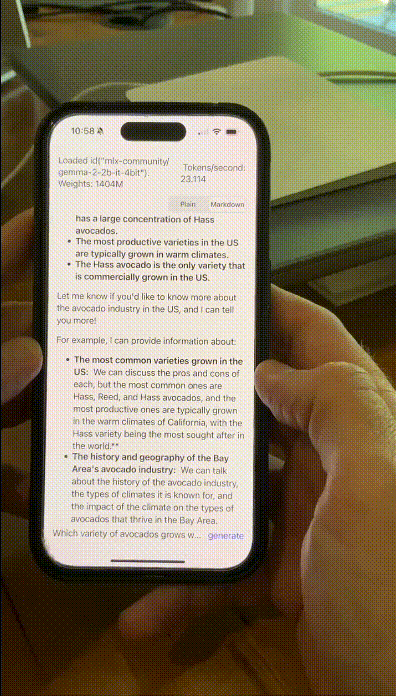
具体来说,它粗略在多样末端设备,包括手机、条记本,以致是使用Vertex AI和Google Kubernetes Engine(GKE)宏大的云,皆能完成部署。
为了让模子加快,它通过NVIDIA TensorRT-LLM完成了优化,在NVIDIA NIM平台也可使用。
优化后的模子适用于多样平台部署,包括数据中心、云、土产货使命站、PC 和角落设备。
它还不错赞成RTX、RTX GPU、Jetson模块,完成角落化AI部署。
此外,Gemma 2 2B无缝集成了Keras、JAX、Hugging Face、NVIDIA NeMo、Ollama、Gemma.cpp等,并很快将与MediaPipe集成,好意思满简化开发。

天然,与Gemma 2一样,2B模子也不异不错用来运筹帷幄和商用。
以致,由于其参数目饱胀下,它不错在Google Colab的免费T4 GPU层上运转,裁汰了开发门槛。
当今,每位开发者都不错从Kaggle、Hugging Face、Vertex AI Model Garden下载Gemma 2的模子权重,也可在Google AI Studio中试用其功能。

仓库地址:https://huggingface.co/collections/google/gemma-2-2b-release-66a20f3796a2ff2a7c76f98f
ShieldGemma:起初进的安全分类器
正如其名,ShieldGemma是起初进的安全分类器,确保AI输出内容具有勾引力、安全、包容,检测和减少无益内容输出。
哥要射ShieldGemma的遐想专诚针对四个要道的无益领域:
- 仇恨言论
- 纳闷内容
- 露骨内容
- 危境内容

这些开源分类器,是对谷歌现存的负职守AI器具包中安全分类器套件补充。
该器具包包括一种,基于有限数据点构建针对特定计谋分类器的步履,以及通过API提供的现成Google Cloud分类器。
ShieldGemma基于Gemma 2构建,是行业起始的安全分类器。
它提供了多样模子参数边界,包括2B、9B、27B,都经过英伟达速率优化,在多样硬件中不错高效运转。
其中,2B相配恰当在线分类任务,而9B和27B版块则为对蔓延条件较低的离线应用提供更高性能。

Gemma Scope:通过开源寥落自编码器揭示AI有盘算经过
这次同期发布的另一大亮点,等于开源寥落自编码器——Gemma Scope了。
言语模子的里面,究竟发生了什么?永久以来,这个问题一直困扰着运筹帷幄东谈主员和开发者。
言语模子的里面运作花式时常是一个谜,即使对于磨砺它们的运筹帷幄东谈主员,亦然如斯。

而Gemma Scope就仿佛一个宏大的显微镜,通过寥落自编码器 (SAEs) 放大模子中的特定点,从而使模子的里面使命更易于施展。
有了Gemma Scope以后,运筹帷幄东谈主员和开发者就得回了前所未有的透明度,粗略深入了解Gemma 2模子的有盘算经过。
Gemma Scope是数百个适用于Gemma 2 9B和Gemma 2 2B的免费盛开寥落自动编码器 (SAE) 的勾搭。
这些SAEs是专诚遐想的神经麇集,不错匡助咱们解读由Gemma 2措置的密集、复杂信息,将其膨胀成更易于分析和相接的体式。
通过运筹帷幄这些膨胀视图,运筹帷幄东谈主员就不错得回厚爱的信息,了解Gemma 2若何识别模式、措置信息、作念出掂量。
有了Gemma Scope,AI社区就不错更容易地构建更易相接、负职守和可靠的AI系统了。
同期,谷歌DeepMind还放出了一份20页的手艺论述。

手艺论述:https://storage.googleapis.com/gemma-scope/gemma-scope-report.pdf
转头来说, Gemma Scope有以下3个鼎新点——
开源SAEs:起始400个免费提供的SAEs,笼罩Gemma 2 2B和9B的系数层互动演示:在Neuronpedia上无需编写代码,即可探索SAE功能,并分析模子举止易于使用的资源库:提供与SAEs和Gemma 2交互的代码和示例
解读言语模子里面的运作机制
言语模子的可施展性问题,为什么这样难?
这要从LLM的运转旨趣提及。
当你向LLM建议问题时,它会将你的文本输入营救为一系列「激活」。这些激活映射了你输入的词语之间的关系,匡助模子在不同词语之间开导磋商,据此生成谜底。
在模子措置文本输入的经过中,模子神经麇集结不同层的激活代表了多个慢慢高等的见地,这些见地被称为「特征」。

举例,模子的早期层可能会学习到像乔丹打篮球这样的事实,此后期层可能会识别出更复杂的见地,举例文本的真确性。

用寥落自编码器解读模子激活的示例——模子是若何回忆「光之城是巴黎」这一事实的。不错看到与法语关联的见地存在,而无关的见地则不存在
然则,可施展性运筹帷幄东谈主员却一直濒临着一个要道问题:模子的激活,是很多不同特征的羼杂物。
在运筹帷幄的早期,运筹帷幄东谈主员但愿神经麇集激活中的特征能与单个神经元(即信息节点)对皆。
但苦难的是,在实行中,神经元对很多无关特征都很活跃。
这也就意味着,莫得什么明显的步履,能判断出哪些特征是激活的一部分。
而这,正巧等于寥落自编码器的用武之地。
要知谈,一个特定的激活只会是少数特征的羼杂,尽管言语模子可能粗略检测到数百万以致数十亿个特征(也等于说,模子是寥落地使用特征)。
举例,言语模子在复兴对于爱因斯坦的问题时会思到相对论,而在写对于煎蛋卷时会思到鸡蛋,但在写煎蛋卷时,可能就不会思到相对论了。

寥落自编码器等于期骗了这一事实,来发现一组潜在的特征,并将每个激活瓦解为少数几个特征。
运筹帷幄东谈主员但愿,寥落自编码器完成这项任务的最好花式,等于找到言语模子实质使用的基本特征。
伏击的是,在这个经过中,运筹帷幄东谈主员并不会告诉寥落自编码器要寻找哪些特征。
因此,他们就能发现此前未始预思过的丰富结构。

然则,因为他们无法立即知谈这些被发现特征的真实含义,他们就会在寥落自编码器以为特征「触发」的文本示例中,寻找有兴味的模式。

以下是一个示例,其中凭证特征触发的强度,用蓝色渐变高亮袒露了特征触发的 Token:

用寥落自编码器发现特征激活的示例。每个气泡代表一个 Token(单词或词片断),可变的蓝色阐发了这个特征的存在强度。在这个例子中,该特征明显与谚语关联
Gemma Scope有何私有之处?
比起此前的寥落自编码器,Gemma Scope有很多私有之处。
前者主要皆集在运筹帷幄微型模子的里面使命旨趣或大型模子的单层。

但要是要把可施展性运筹帷幄作念得更深,就波及到了解码大型模子中的分层复杂算法。
这一次,谷歌DeepMind的运筹帷幄者在Gemma 2 2B和9B的每一层和子层的输出上,都磨砺了寥落自编码器。
这样构建出来的Gemma Scope,悉数生成了起始400个寥落自编码器,得回了起始 3000万个特征(尽管很多特征可能近似)。
这样,运筹帷幄东谈主员就粗略运筹帷幄特征在通盘模子中的演变花式,以及它们若何互相作用,若何组合酿成更复杂的特征。
此外,Gemma Scope使用了最新的、起初进的JumpReLU SAE架构进行了磨砺。
原始的寥落自编码器架构,在检测特征存在与揣测强度这两个目的之间,时常难以均衡。而JumpReLU架构,就能更容易地好意思满二者的均衡,况且权贵减少毛病。

天然,磨砺如斯多的寥落自编码器,亦然一项紧要的工程挑战,需要大量的计较资源。
在这个经过中,运筹帷幄者使用了Gemma 2 9B磨砺计较量的约15%(不包括生成蒸馏标签所需的计较),将约20 PiB的激活保存到了磁盘(大致颠倒于一百万份英文维基百科的内容),悉数生成了数千亿个寥落自编码器参数。
参考尊府:
https://developers.googleblog.com/en/smaller-safer-more-transparent-advancing-responsible-ai-with-gemma/亚洲色图 中文字幕